
Convolutional Layers (auf Deutsch: Faltungsschichten) sind das Herzstück von Convolutional Neural Networks (CNNs). Sie bilden die Grundlage für viele moderne Anwendungen in der Bildverarbeitung, Mustererkennung, medizinischen Bildanalyse und sogar in der Verarbeitung von Audiodaten.
Ein Convolutional Layer dient dazu, aus den Eingabedaten (z. B. einem Bild) lokale Merkmale zu extrahieren. Diese Schichten ermöglichen es, Muster wie Kanten, Texturen oder komplexere Strukturen zu erkennen – und das positionsunabhängig.
Grundlagen der Faltung
Die zentrale Operation eines Convolutional Layers ist die diskrete Faltung. Dabei wird ein kleiner Filter (auch Kernel genannt) über die Eingabe geschoben. An jeder Position wird das Skalarprodukt zwischen den Filtergewichten und dem entsprechenden Ausschnitt der Eingabedaten berechnet.
Beispiel einer 2D-Faltung:
Angenommen, ein 3×3-Kernel wird über ein 5×5-Bild bewegt, dann sieht die Operation schematisch so aus:
Input (5x5) Filter (3x3) Output (3x3)
[ 1 2 3 0 1 ] [ 1 0 -1 ] [...]
[ 4 5 6 1 0 ] (*) [ 1 0 -1 ] => [...]
[ 7 8 9 0 1 ] [ 1 0 -1 ] [...]
[ 1 1 1 1 1 ]
[ 0 0 1 2 3 ]
In der Realität ist der Input deutlich größer und die Filter-Gewichte nicht exakt 1, 0 oder – 1 (da sie in einem Float-Datentyp gelernt wurden).
Das Ergebnis ist eine Feature Map – eine neue Matrix, die anzeigt, wie stark das jeweilige Muster (z. B. eine Kante) an verschiedenen Positionen im Bild erkannt wurde.
Aufbau eines Convolutional Layers
Ein Convolutional Layer besteht aus mehreren Filtern. Jeder dieser Filter ist darauf trainiert, ein spezifisches Merkmal zu erkennen. Die Filtergewichte werden beim Training durch Backpropagation angepasst.
Komponenten im Detail:
- Filter/Kernels: Kleine Matrizen (z. B. 3×3, 5×5), die mit der Eingabe gefaltet werden.
- Stride: Gibt an, wie viele Pixel der Filter bei jedem Schritt springt.
- Padding: Steuerung, ob die Ränder der Eingabe durch zusätzliche Pixel (z. B. Nullen) erweitert werden.
- Bias-Term: Ein konstanter Wert, der zur Ausgabe jedes Filters addiert wird.
- Aktivierungsfunktion: Wird auf das Ergebnis der Faltung angewendet, um Nichtlinearitäten einzuführen.
Hyperparameter und deren Bedeutung
| Hyperparameter | Beschreibung |
|---|---|
filters | Anzahl der Filter, bestimmt die Tiefe der Ausgabe. Jeder Filter lernt ein anderes Merkmal. |
kernel_size | Größe des Filters, z. B. (3,3) oder (5,5). |
strides | Wie stark der Filter bei jeder Anwendung verschoben wird. |
padding | Ob die Eingabe an den Rändern erweitert wird, um die Ausgabegröße zu beeinflussen (valid oder same). |
activation | ReLU, sigmoid, tanh usw. – Einführt Nichtlinearität in die Ausgabe. |
Vorteile von Convolutional Layers
- Parameter-Sharing: Alle Positionen im Bild verwenden denselben Filter, was die Anzahl der Parameter stark reduziert.
- Translation Invariance: Merkmale werden unabhängig von ihrer Position erkannt.
- Reduzierte Komplexität: Verglichen mit voll verbundenen Schichten sind deutlich weniger Parameter notwendig.
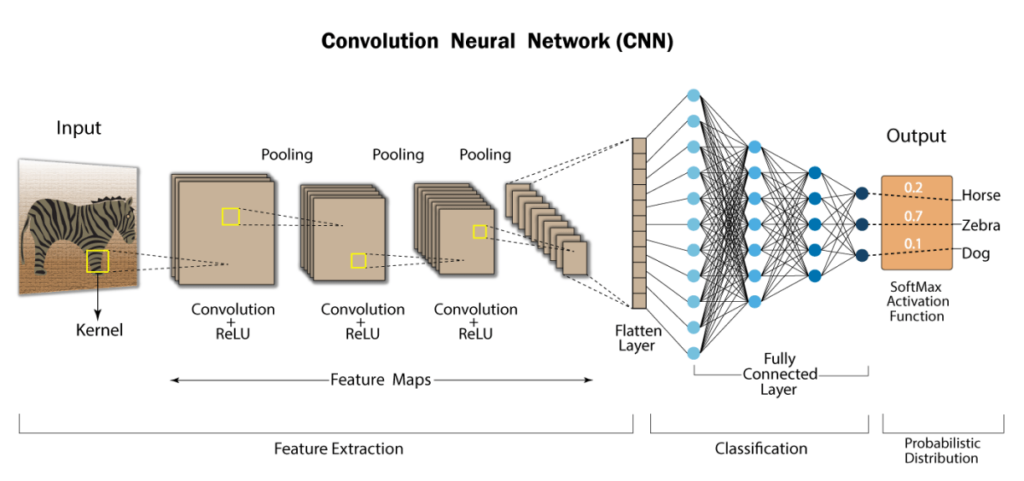
Beispiel mit tf.keras.layers.Conv2D
Im folgenden Beispiel wird ein einfacher CNN-Block mit TensorFlow/Keras definiert:
pythonCopyimport tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1),
padding='same', activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(10, activation='softmax')
])
model.summary()
Erklärung:
Conv2D(...): Faltungsschicht mit 32 3×3-Filtern und ReLU-Aktivierung.MaxPooling2D: Reduziert die Dimension der Feature Maps und erhält (meist) die von Conv2D betonte Charakteristik. MaxPooling2D wird meist nach ein Conv2D geschaltet.Flatten: Wandelt die mehrdimensionale Ausgabe in einen Vektor um, bevor die Feature-Map in eine „normale“ Dense-Schicht weitergegeben wird.Dense: Klassifikationsschicht mit 10 Neuronen für 10 Klassen (z. B. MNIST).
Anwendung in der Praxis
Convolutional Layers werden in vielen Anwendungen eingesetzt:
- Bilderkennung (z. B. Objekterkennung, Gesichtserkennung)
- Klassifikation medizinischer Bilddaten
- Verkehrszeichenerkennung in autonomen Fahrzeugen
- Verarbeitung von Audiodaten (z. B. Sprachkommandos)
Convolutional Layers sind zentrale Bausteine moderner Deep-Learning-Modelle. Sie ermöglichen eine effiziente und leistungsstarke Extraktion von Merkmalen und bilden damit die Grundlage für viele Anwendungen in der KI. Durch ein gutes Verständnis der Faltung, Hyperparameter und Architektur kann gezielt Einfluss auf die Leistung eines Modells genommen werden.