
In diesem Artikel lernen Sie, wie Sie mit TensorFlow und Keras ein neuronales Netz erstellen, das handgeschriebene Ziffern des MNIST-Datensatzes klassifiziert. Der MNIST-Datensatz ist einer der bekanntesten und am häufigsten genutzten Datensätze für das Training und die Evaluation von Modellen zur Bildklassifikation. Zudem ist MNIST open-source, was bedeutet, dass er frei und öffentlich zugänglich ist. So kann jeder Entwickler oder Forscher mit diesem Datensatz experimentieren und ihn in eigenen Projekten nutzen.
1. Der MNIST-Datensatz: Geschichte und Bedeutung
Der MNIST-Datensatz (Modified National Institute of Standards and Technology) wurde in den 1990er Jahren von den Forschern Yann LeCun, Corinna Cortes und Christopher Burges entwickelt. Ursprünglich als Teil eines größeren Datensatzes handgeschriebener Zahlen für die US-Postdienst-Erkennung vorgesehen, wurde MNIST speziell für das Testen von Klassifikationsmodellen vorbereitet und vereinfacht.
Der Datensatz besteht aus handgeschriebenen Zahlen von 0 bis 9 und enthält 60.000 Trainings- sowie 10.000 Testbilder. Jedes Bild ist in Graustufen und hat eine Auflösung von 28 x 28 Pixeln. Diese Aufgabe ist komplex, da die Handschrift je nach Person stark variieren kann, aber dennoch kompakt genug, dass Modelle auf einem normalen Rechner in kurzer Zeit trainiert werden können und damit ideal für unser Tutorial.

Link zum MNIST-Datensatz: Den MNIST-Datensatz hier direkt herunterladen und die Bilder im Detail ansehen.
2. Ein größeres Neuronales Netz für MNIST
Im Vergleich zu vorherigen Tutorialartikeln arbeiten wir hier mit einem größeren neuronalen Netz. Durch die zusätzlichen Neuronen kann das Modell die Variationen in den handgeschriebenen Ziffern besser lernen. Die Modellarchitektur umfasst insgesamt drei Dense-Schichten, die das Netzwerk in die Lage versetzen, komplexere Zusammenhänge zu erkennen, bleibt aber dennoch kompakt genug, um in wenigen Minuten zu trainieren.
Die Konfiguration dieses neuronalen Netzes basiert weniger auf einer festen Theorie und wurde hauptsächlich durch „Try-and-Error“ herausgefunden, indem verschiedene Schichtgrößen und -anzahlen sowie Konfigurationen ausprobiert wurden, um eine gute Balance zwischen Leistung und Geschwindigkeit zu finden.
3. Batches im Training: Effizientes Lernen
In diesem Modell wird mit einem Batch-Size von 32 trainiert. Ein Batch beschreibt die Anzahl der Beispiele, die das Netzwerk vor einem Parameterupdate verarbeitet. Batches spielen eine wesentliche Rolle für die Effizienz des Training:
- Speichereffizienz: Anstatt den gesamten Trainingsdatensatz auf einmal zu laden und zu verarbeiten, nutzt das Netzwerk kleinere Datenblöcke, wodurch weniger Speicher beansprucht wird.
- Optimierungseffizienz: Da die Gewichte des Modells nach jedem Batch angepasst werden, ermöglicht dies schnelleres Lernen und verhindert Überanpassungen an einzelnen Datensätzen.
Batches helfen einem auch komplexe, große Datensätze mit großen neuronalen Netzen zu verarbeiten: Es müssen nicht alle Daten in RAM geladen werden, so dass der RAM nicht zwingend so groß wie der Datensatz sein muss – d.h. Batching stellt eine einfache Möglichkeit dar mit mangelnde RAM-Resourcen umzugehen.
Das Modell wird hier in nur 5 Epochen trainiert, das heißt, der gesamte Trainingssatz wird fünfmal durchlaufen und nach jedem Batch von 32 Bildern erfolgt ein Gewichtungsupdate.
4. Python-Code zur Umsetzung des MNIST-Klassifikationsmodells
Hier ist der vollständige Code, der die oben beschriebenen Schritte in TensorFlow und Keras umsetzt. Dieser Code ist in Google Colab lauffähig und gibt am Ende die Genauigkeit des Modells auf dem Test-Datensatz aus:
# Importieren der benötigten Bibliotheken
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import mnist
# Laden des MNIST-Datensatzes
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Vorverarbeiten der Daten
x_train, x_test = x_train / 255.0, x_test / 255.0 # Normalisierung der Graustufen-Pixel [Werte von 0 bis 255] auf den Bereich 0 bis 1
# Modellarchitektur erstellen
model = Sequential([
Flatten(input_shape=(28, 28)), # Eingabe-Ebene: Zweidimensionales Bild wird in einen Vektor umgewandelt
Dense(128, activation='relu'), # Versteckte Ebene mit 128 Neuronen und ReLU-Aktivierung
Dense(64, activation='relu'), # Weitere versteckte Ebene mit 64 Neuronen
Dense(10, activation='softmax') # Ausgabeschicht mit 10 Neuronen für die Klassen 0–9
])
# Modell kompilieren
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Modell trainieren
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.1)
# Modell auf dem Test-Datensatz bewerten
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_accuracy * 100:.2f}%")
Eine grafische Darstellung der Klassengrenzen bzw. wie sie sich über die Epochen hinweg angepasst werden ist hier nicht mehr möglich, da die es nicht wie bei vorherigen Beispielen nur 2 Eingangswerte gibt, sondern 784 (28 x 28 Pixel). Daher nutzen wir die Keras-eigene Darstellung der Angabe der Akkurität zum Überwachen des Trainingsfortschrittes (und verzichten damit auf reichlich Code für die Darstellung und insb. die for-Loop).
Python-Ausgabe:
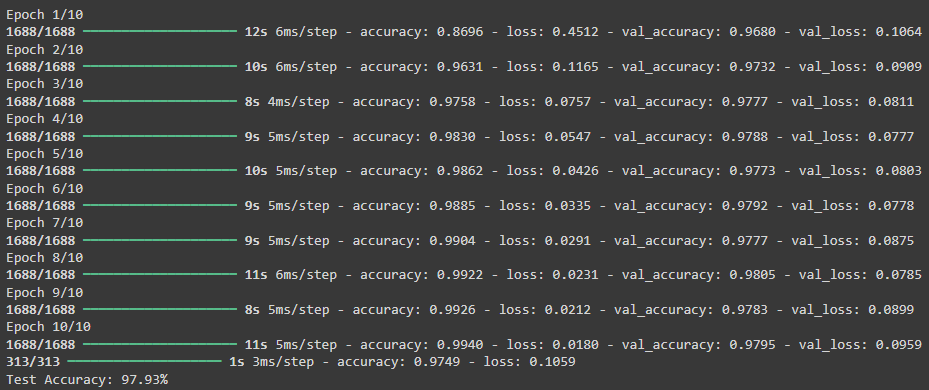
In diesem Tutorial wurde ein einfaches neuronales Netz auf dem MNIST-Datensatz trainiert. Mit einer Genauigkeit von deutlich über 90 % ist das Modell gut in der Lage, handgeschriebene Zahlen zu klassifizieren (ein einfaches Raten der Zahlen hätte nur eine Genauigkeit von 10%). Komplexere Netz bzw. längere Trainingszeiten können Werte von über 99% erreichen – probieren Sie gerne selbst aus, was Ihr persönlicher Rekord ist..