
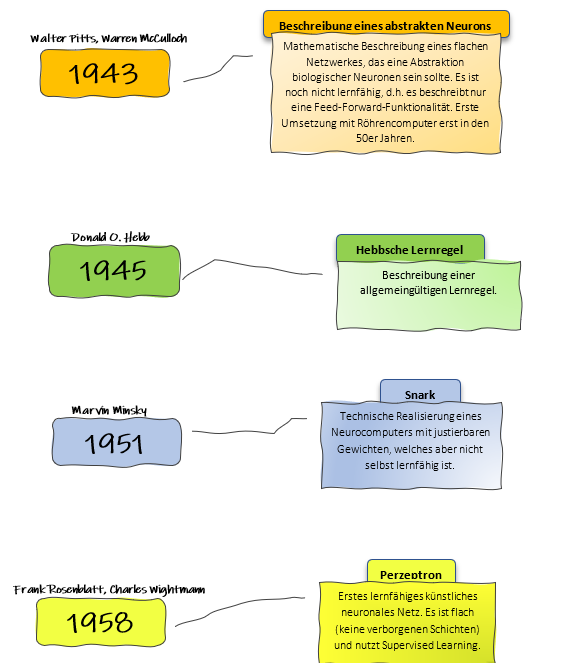
1943: Mathematische Beschreibung eines abstrakten Neurons
Walter Pitts und Warren McCulloch waren zwei Pioniere, die 1943 die erste mathematische Beschreibung eines abstrakten Neurons entwickelten. Ihr Modell, bekannt als McCulloch-Pitts-Neuron, war der erste Versuch, die Funktionsweise biologischer Neuronen durch mathematische Logik zu abstrahieren. Sie stellten sich ein neuronales Netzwerk vor, das aus mehreren solcher Neuronen bestand, die als binäre Einheiten funktionierten – sie waren entweder „an“ oder „aus“.
Dieses Modell bildete die Grundlage für das, was wir heute als „Feed-Forward“-Netzwerke kennen, bei denen Informationen in eine Richtung durch das Netzwerk fließen, ohne Rückkopplungsschleifen oder Lernmechanismen. Zwar konnten diese frühen Netzwerke keine Informationen „lernen“, aber die Arbeit von Pitts und McCulloch legte den Grundstein für zukünftige Entwicklungen in der künstlichen Intelligenz. Eine praktische Umsetzung dieses Konzepts mit Röhrencomputern fand erst in den 1950er Jahren statt.
1945: Hebbsche Lernregel
Zwei Jahre später, 1945, formulierte der kanadische Psychologe Donald O. Hebb die nach ihm benannte Hebbsche Lernregel. Diese Regel war einer der ersten Ansätze, um zu erklären, wie Neuronen durch Lernen ihre Verbindungen anpassen könnten. Hebb postulierte, dass die Stärke der Verbindung zwischen zwei Neuronen erhöht wird, wenn beide gleichzeitig aktiv sind – eine Idee, die später zusammengefasst wurde in dem Satz: „Neurons that fire together, wire together“.
Obwohl Hebb diese Regel ursprünglich auf biologische Neuronen anwendete, hatte seine Theorie einen enormen Einfluss auf die Entwicklung künstlicher neuronaler Netze. Die Hebbsche Lernregel war ein wichtiger erster Schritt in Richtung eines lernfähigen Netzwerks, auch wenn sie in den ersten neuronalen Netzwerken noch nicht umgesetzt wurde.
1951: Snark von Marvin Minsky
1951 entwickelte Marvin Minsky, einer der führenden Köpfe in der frühen KI-Forschung, den sogenannten „Snark“ – einen der ersten Neurocomputer. Snark war ein einfaches, technisches System, das auf die theoretischen Konzepte von McCulloch und Pitts aufbaute. Es war in der Lage, mit justierbaren Gewichten zu arbeiten, die die Stärke der Verbindungen zwischen den „Neuronen“ im System beeinflussten.
Jedoch war Snark, ähnlich wie die früheren Modelle, noch nicht in der Lage zu lernen. Es war eine technische Demonstration dessen, wie künstliche Neuronen auf physischer Ebene umgesetzt werden könnten. Obwohl es also nicht den Durchbruch in Richtung lernfähiger Netze darstellte, markierte es einen wichtigen Schritt auf dem Weg zu komplexeren neuronalen Netzwerken.
1958: Perzeptron – Das erste lernfähige künstliche Neuronale Netz
Der wichtigste Meilenstein in der frühen Entwicklung künstlicher neuronaler Netze kam 1958, als Frank Rosenblatt und Charles Wightman das Perzeptron vorstellten. Das Perzeptron war das erste künstliche neuronale Netz, das in der Lage war, durch sogenanntes „supervised Learning“ (überwachtes Lernen) zu lernen. Es handelte sich um ein flaches Netzwerk, das keine verborgenen Schichten besaß, aber die Gewichte der Verbindungen zwischen den Neuronen anhand von Eingabedaten und einem angestrebten Ergebnis anpassen konnte.
Rosenblatts Perzeptron konnte grundlegende Aufgaben der Mustererkennung bewältigen und markierte den ersten großen Durchbruch hin zu lernenden Maschinen. Obwohl dieses Modell im Laufe der Zeit aufgrund seiner Beschränkungen (wie der Unfähigkeit, nicht-lineare Probleme zu lösen) kritisiert wurde, bildete es dennoch den Ausgangspunkt für die spätere Entwicklung tieferer neuronaler Netze mit mehreren Schichten und verbesserten Lernalgorithmen.
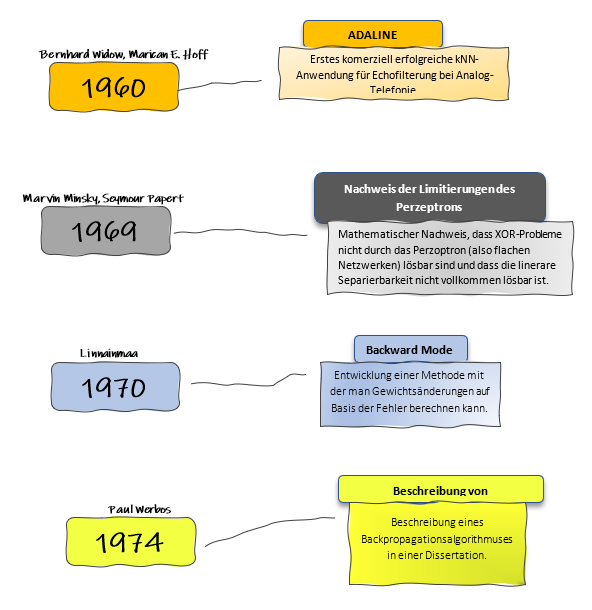
1960: ADALINE – Ein kommerzieller Durchbruch
ADALINE (Adaptive Linear Neuron) wurde 1960 von Bernhard Widrow und Marican E. Hoff entwickelt und war eines der ersten neuronalen Netzwerke, das erfolgreich in kommerziellen Anwendungen eingesetzt wurde. ADALINE basierte auf dem Konzept eines künstlichen Neurons, das in der Lage war, Gewichte zu ändern, um durch eine lineare Kombination von Eingabedaten Muster zu erkennen.
Sein kommerzieller Erfolg kam durch den Einsatz in der Echofilterung bei analogen Telefonsystemen. ADALINE wurde verwendet, um Störsignale in Telefongesprächen zu eliminieren. Dieses System war eine der ersten praktischen Anwendungen eines künstlichen neuronalen Netzwerks und zeigte, dass neuronale Netzwerke nicht nur in der Theorie existieren, sondern reale Probleme lösen konnten.
1969: Der Nachweis der Limitierungen des Perzeptrons
1969 veröffentlichten Marvin Minsky und Seymour Papert ihr einflussreiches Buch Perceptrons, in dem sie die Grenzen des einfachen Perzeptron-Modells aufzeigten. Eine der wichtigsten Erkenntnisse aus ihrer Arbeit war, dass Perzeptrons, also neuronale Netze ohne versteckte Schichten, grundlegende Probleme wie die XOR-Funktion nicht lösen konnten. Dies liegt daran, dass das Perzeptron nur lineare Beziehungen zwischen Eingaben und Ausgaben erkennen kann, aber nichtlineare Probleme, wie sie in der XOR-Funktion auftreten, nicht bewältigen kann.
Diese Arbeit führte dazu, dass viele Forscher in den folgenden Jahren das Interesse an neuronalen Netzen verloren, da man davon ausging, dass ihre Fähigkeiten begrenzt seien. Erst später, mit der Einführung von mehrschichtigen Netzwerken und neuen Lernmethoden, sollten neuronale Netze wieder in den Fokus der Forschung rücken.
1970: Backward Mode – Die Geburtsstunde der effizienten Fehlerberechnung
Dieser wichtige Meilenstein kam 1970, als Seppo Linnainmaa den sogenannten Backward Mode entwickelte. Diese Methode ermöglichte es, die Ableitungen einer Funktion effizient zu berechnen, insbesondere im Hinblick auf die Gewichtsänderungen in neuronalen Netzen. Diese Entwicklung legte die theoretische Grundlage für spätere Algorithmen, die es ermöglichen sollten, Netzwerke mit mehreren Schichten zu trainieren.
Durch die Berechnung des Fehlers und die Rückpropagation dieses Fehlers durch das Netzwerk war es möglich, die Gewichte systematisch zu justieren, um die Leistung des Netzwerks zu verbessern. Der Backward Mode war somit ein wichtiger Schritt in Richtung der Entwicklung des Backpropagationsalgorithmus, der in den 1980er Jahren maßgeblich zur Wiederentdeckung und zum Aufstieg neuronaler Netze beitragen sollte.
1974: Die formelle Beschreibung des Backpropagationsalgorithmus
1974 folgte ein weiterer Durchbruch: Paul Werbos beschrieb in seiner Dissertation den Backpropagationsalgorithmus, der die effiziente Berechnung von Fehlern und Gewichtsänderungen in mehrschichtigen neuronalen Netzen ermöglichte. Backpropagation (Rückwärtsausbreitung) war die Antwort auf das Problem, das Minsky und Papert 1969 aufgezeigt hatten – nämlich die Unfähigkeit von Perzeptrons, nichtlineare Probleme zu lösen.
Der Backpropagationsalgorithmus erlaubt es einem Netzwerk, Fehler zwischen den vorhergesagten und tatsächlichen Ergebnissen zu berechnen und diesen Fehler durch das Netzwerk zurückzuführen, um die Gewichte entsprechend zu aktualisieren. Dies ermöglichte erstmals das Training von tiefen neuronalen Netzwerken mit mehreren Schichten und legte den Grundstein für die heutigen „Deep Learning“-Technologien.
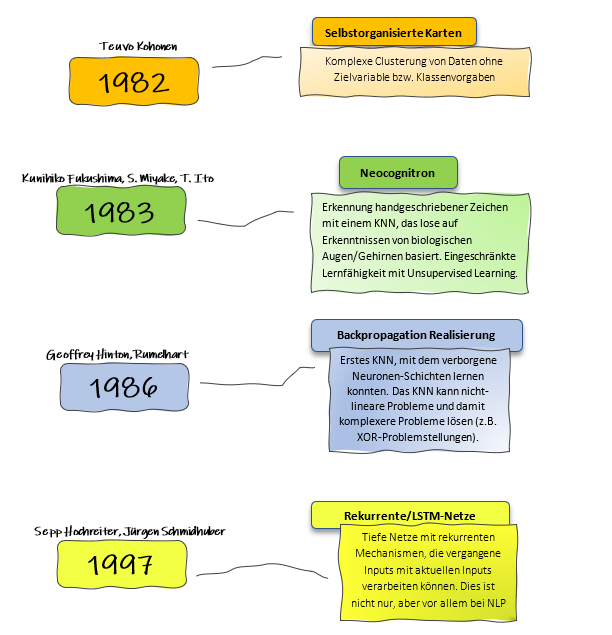
1982: Selbstorganisierte Karten (Self-Organizing Maps) von Teuvo Kohonen
Teuvo Kohonen stellte 1982 das Konzept der selbstorganisierten Karten (Self-Organizing Maps, SOM) vor, eine Technik des unüberwachten Lernens. Diese Methode ermöglicht es, große Datensätze ohne vorgegebene Zielvariablen oder Klassenvorgaben in Cluster zu ordnen. SOMs projizieren hochdimensionale Daten auf eine niedrigdimensionale Karte und bilden dabei Cluster, die ähnliche Datenpunkte gruppieren.
Selbstorganisierte Karten sind besonders nützlich für Anwendungen, bei denen es darauf ankommt, Ähnlichkeiten oder Muster in Daten zu erkennen, ohne dass im Vorfeld klare Klassifizierungen oder Zielvorgaben vorliegen. Diese Technik fand Anwendung in Bereichen wie der Datenvisualisierung und dem Data Mining und half, besser zu verstehen, wie maschinelles Lernen Daten verarbeiten und kategorisieren kann.
2. 1983: Neocognitron – Frühes Vorbild für Convolutional Neural Networks (CNNs)
Ein Jahr später, 1983, entwickelten Kunihiko Fukushima, S. Miyake und T. Ito das Neocognitron, ein wichtiges neuronales Netzwerkmodell, das auf die Erkennung handgeschriebener Zeichen spezialisiert war. Das Neocognitron war das erste Modell, das die Idee von mehrschichtigen hierarchischen Strukturen einführte, die später als Inspiration für Convolutional Neural Networks (CNNs) dienten.
Das Neocognitron zeichnete sich durch seine Fähigkeit aus, visuelle Muster unabhängig von ihrer Position im Bild zu erkennen, was für Aufgaben wie die Erkennung handgeschriebener Zeichen entscheidend war. Die Arbeit von Fukushima und seinen Kollegen legte den Grundstein für spätere Entwicklungen in der Computer Vision und bildete die Basis für heutige Bildverarbeitungstechnologien, die in der Lage sind, komplexe visuelle Daten zu analysieren.
3. 1986: Die Realisierung von Backpropagation – Der Durchbruch des tiefen Lernens
1986 machten Geoffrey Hinton und David Rumelhart einen entscheidenden Schritt in der Entwicklung neuronaler Netze, indem sie den Backpropagationsalgorithmus in die Praxis umsetzten. Dieser Algorithmus ermöglichte es erstmals, tiefe neuronale Netze mit mehreren Schichten effizient zu trainieren, einschließlich verborgener Neuronen-Schichten, die zur Lösung komplexer, nicht-linearer Probleme wie dem XOR-Problem benötigt werden.
Die Einführung von Backpropagation revolutionierte die KI-Forschung, da neuronale Netze nun in der Lage waren, durch die Anpassung der Gewichte in den Schichten zu „lernen“. Diese Methode erwies sich als leistungsstark für eine Vielzahl von Anwendungen, einschließlich der Bilderkennung, Sprachverarbeitung und Mustererkennung. Sie war ein grundlegender Meilenstein, der die Entwicklung tiefer Netzwerke, also des heutigen „Deep Learning“, möglich machte. Aber mehrere Punkte verhinderten den großen Durchbruch: Mangelnde Datensätze zum Trainieren, zu schwache HW und das Problem des „Vanishing Gradient“, der dafür sorgte, dass tiefere Schichten nicht so stark trainiert wurden wie die ersten Schichten.
41997: Rekurrente Neuronale Netze und LSTM – Die Lösung für sequenzielle Daten
Ein weiterer bedeutender Fortschritt kam 1997 mit der Einführung rekurrenter neuronaler Netze (RNNs) und insbesondere der LSTM-Netze (Long Short-Term Memory) durch Sepp Hochreiter und Jürgen Schmidhuber. Rekurrente Netze zeichnen sich dadurch aus, dass sie über einen Mechanismus verfügen, der es ermöglicht, vergangene Eingaben in ihre aktuellen Berechnungen einzubeziehen, was besonders für sequenzielle Daten wie Text, Sprache oder Zeitreihen wichtig ist.
LSTM-Netze machten es möglich, langfristige Abhängigkeiten in Daten zu lernen. Diese Entwicklung war besonders für die Verarbeitung natürlicher Sprache (NLP) sowie für andere Anwendungen im Bereich der Zeitreihenanalyse bahnbrechend. LSTMs sind heute ein zentraler Bestandteil vieler moderner KI-Anwendungen, insbesondere in der Verarbeitung von Text und Sprache.
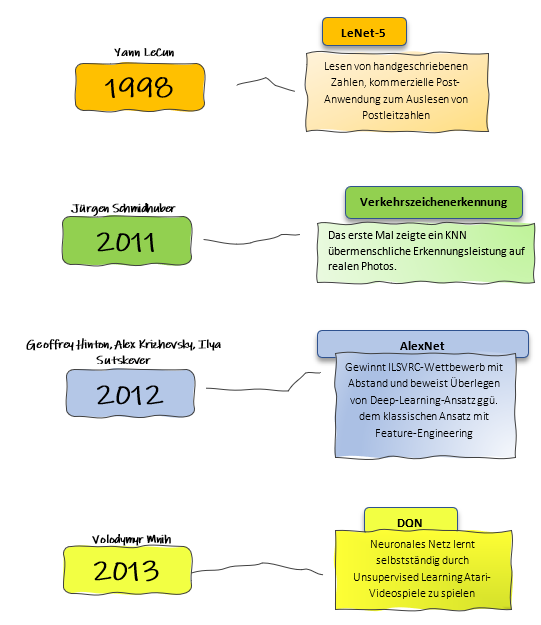
1998: LeNet-5 – Der Durchbruch für Convolutional Neural Networks (CNNs)
Yann LeCun entwickelte 1998 LeNet-5, ein bahnbrechendes Convolutional Neural Network (CNN), das speziell für die Erkennung handgeschriebener Ziffern entwickelt wurde. Es war eines der ersten CNN-Modelle, das erfolgreich in kommerziellen Anwendungen eingesetzt wurde, insbesondere im Bereich der Postautomatisierung. LeNet-5 wurde verwendet, um Postleitzahlen auf handschriftlichen Dokumenten und Paketen zu erkennen und zu verarbeiten – eine Aufgabe, die zuvor mühsam manuell durchgeführt werden musste.
LeNet-5 war nicht nur ein praktischer Erfolg, sondern legte den Grundstein für die moderne Bildverarbeitungstechnologie. CNNs, die auf den Prinzipien von LeNet-5 basieren, wurden später für eine Vielzahl von Aufgaben verwendet, von der Objekterkennung in Bildern bis hin zur medizinischen Bildanalyse. Das Besondere an CNNs ist ihre Fähigkeit, mithilfe von Faltungsschichten (Convolutional Layers) Merkmale hierarchisch aus Bildern zu extrahieren, wobei frühe Schichten einfache Merkmale wie Kanten und spätere Schichten komplexere Muster erfassen.
CNNs revolutionierten die Bildverarbeitung, weil sie es ermöglichen, Muster unabhängig von ihrer Position im Bild zu erkennen, was sie besonders leistungsfähig macht. LeNet-5 zeigte erstmals, dass tiefere neuronale Netze für visuelle Aufgaben extrem effektiv sein können. Dies ebnete den Weg für weitere Entwicklungen wie AlexNet (2012), VGGNet und ResNet, die die Leistung von CNNs weiter verbesserten und ihren Einsatz in verschiedensten industriellen und wissenschaftlichen Anwendungen etablierten.
Heute sind CNNs ein unverzichtbares Werkzeug in vielen Bereichen der Künstlichen Intelligenz, von selbstfahrenden Autos über Gesichtserkennung bis hin zur medizinischen Diagnostik. LeNet-5 war der erste große Schritt in diese Richtung und bleibt ein wichtiger Meilenstein in der Geschichte der neuronalen Netze.
2011: Verkehrsschilderkennung – Übermenschliche Leistung
2011 markierte einen weiteren wichtigen Meilenstein in der KI, als Jürgen Schmidhubers Team neuronale Netze einsetzte, die erstmals eine übermenschliche Leistung bei der Erkennung von Verkehrsschildern auf Fotos erzielten. Dies war ein bedeutender Schritt, da es bewies, dass neuronale Netze nicht nur theoretische Modelle waren, sondern in realen Aufgaben, die für Menschen entscheidend sind, herausragende Leistungen erbringen konnten.
Die Verkehrsschilderkennung zeigte, dass neuronale Netze nun in der Lage waren, Bilder mit hoher Genauigkeit zu analysieren und zu klassifizieren, was den Weg für fortgeschrittenere Systeme der maschinellen Bilderkennung, wie selbstfahrende Autos, ebnete. Diese Entwicklung verdeutlichte das enorme Potenzial von KI-Systemen im Alltag und bei der Automatisierung sicherheitskritischer Aufgaben.
2012: AlexNet – Der Durchbruch im Deep Learning
Ein Jahr später, 2012, gewannen Geoffrey Hinton, Alex Krizhevsky und Ilya Sutskever mit ihrem Modell AlexNet den ILSVRC-Wettbewerb (ImageNet Large Scale Visual Recognition Challenge) mit deutlichem Vorsprung. AlexNet war ein tiefes neuronales Netzwerk, das acht Schichten und Convolutional Layers nutzte, um Bilddaten zu verarbeiten. Der Erfolg von AlexNet zeigte eindrucksvoll, wie viel leistungsfähiger tiefes Lernen (Deep Learning) im Vergleich zu herkömmlichen maschinellen Lernverfahren mit aufwändigem Feature-Engineering war.
AlexNet markierte einen Wendepunkt in der Geschichte der künstlichen Intelligenz, da es das enorme Potenzial tiefer neuronaler Netze für Aufgaben wie die Bilderkennung offenbarte. Es bewies, dass neuronale Netze mit ausreichender Rechenleistung und großen Datenmengen überragende Ergebnisse erzielen können. Dies beschleunigte das Wachstum und die Verbreitung von Deep-Learning-Anwendungen in verschiedensten Bereichen, von der Gesundheitsdiagnose bis hin zur automatischen Bilderkennung in sozialen Medien.
2013: DQN – Lernen durch Spielen
Ein weiterer Meilenstein wurde 2013 erreicht, als Volodymyr Mnih und sein Team das Deep Q-Network (DQN) entwickelten, das neuronale Netze dazu befähigte, Videospiele selbstständig zu erlernen. Mit DQN war es möglich, dass ein neuronales Netz durch unüberwachtes Lernen Atari-Spiele spielte und dabei Fähigkeiten entwickelte, die besser als die vieler menschlicher Spieler waren.
DQN kombinierte neuronale Netze mit Reinforcement Learning (Verstärkungslernen), um die optimale Handlungsstrategie zu erlernen, ohne dass spezifische Regeln vorab programmiert werden mussten. Dies war ein großer Fortschritt im Bereich des maschinellen Lernens, da es zeigte, dass neuronale Netze in der Lage sind, komplexe Aufgaben eigenständig zu meistern, nur durch das Beobachten und Interagieren mit einer Umgebung.
2014: GANs – Täuschend echte Bilder durch neuronale Netze
Yoshua Bengio und seine Kollegen führten 2014 Generative Adversarial Networks (GANs) ein, eine Methode, bei der zwei neuronale Netze miteinander „konkurrieren“, um realistische Daten zu generieren. Ein Netzwerk, der Generator, erzeugt neue Daten, während das andere, der Diskriminator, versucht zu unterscheiden, ob die Daten echt oder künstlich sind. Durch diese Konkurrenz lernt der Generator, immer bessere und täuschend echt wirkende Bilder zu produzieren.
GANs haben enorme Fortschritte in der Bild- und Videogenerierung gebracht. Sie sind in der Lage, realistische Bilder von Menschen, Landschaften und sogar Kunstwerken zu erschaffen, die es vorher nicht gab. GANs haben auch viele Anwendungen im Bereich der künstlichen Bildsynthese, wie in der Medizin, der Kunst und der Unterhaltung.
2016: AlphaGo und AlphaGo Zero – Meister der Brettspiele
2016 erreichte die KI einen neuen Höhepunkt, als DeepMinds AlphaGo den weltbekannten Go-Meister Lee Sedol schlug. Go galt lange als eines der komplexesten Brettspiele, das schwer für Maschinen zu beherrschen sei. AlphaGo verwendete eine Kombination aus neuronalen Netzen und Monte-Carlo-Simulationen, um menschliche Expertise zu übertreffen.
Kurz darauf wurde AlphaGo Zero entwickelt, das ohne Vorwissen über das Spiel lernte und nur durch das Spielen gegen sich selbst übermenschliche Fähigkeiten entwickelte. Innerhalb kürzester Zeit schlug AlphaGo Zero sogar die ursprüngliche AlphaGo-Version. Dieser Fortschritt zeigte die unglaubliche Lernfähigkeit neuronaler Netze, ohne auf menschliche Daten angewiesen zu sein, und ebnete den Weg für generalisierbare Lernsysteme.
2017: AlphaZero – Meister aller Brettspiele
Ein Jahr nach dem Erfolg von AlphaGo folgte AlphaZero, eine Weiterentwicklung, die nicht nur Go beherrschte, sondern auch Schach und Shogi (japanisches Schach). AlphaZero lernte alle drei Spiele ohne menschliches Wissen und entwickelte in jedem eine übermenschliche Stärke, die alle bekannten Programme und Spieler übertraf.
Der Erfolg von AlphaZero demonstrierte die Vielseitigkeit und Generalisierungsfähigkeit neuronaler Netze in unterschiedlichen, komplexen Problembereichen. AlphaZero ist nicht nur in der Lage, sich in einem Spiel zu spezialisieren, sondern auch in verschiedenen Domänen zu brillieren, was für die Entwicklung zukünftiger universeller KI-Systeme von großer Bedeutung ist.
2017: Self-Attention – Der Quantensprung in der Sprachverarbeitung
Ebenfalls 2017 veröffentlichten Ashish Vaswani und sein Team von Google Brain das bahnbrechende Paper “Attention is All You Need“, in dem sie das Self-Attention-Modell vorstellten. Dieser Ansatz ermöglichte es, den Kontext in Sequenzen (z. B. in Texten) effizienter zu verarbeiten, indem er fokussiert analysierte, welche Teile der Eingabe für die Ausgabe am wichtigsten sind.
Self-Attention revolutionierte das Gebiet der natürlichen Sprachverarbeitung (NLP) und wurde zur Grundlage moderner Sprachmodelle wie GPT und BERT. Diese Modelle sind in der Lage, kontextuelle Informationen in Texten viel besser zu verstehen und zu verarbeiten als frühere Ansätze. Dies führte zu enormen Fortschritten in Bereichen wie Übersetzung, Textgenerierung und Sprachverständnis.
2022: Midjourney und DALL-E – Der Durchbruch der Bildgenerierung durch KI
2022 war ein Jahr bahnbrechender Fortschritte in der Bildgenerierung durch Künstliche Intelligenz. Zwei herausragende Plattformen, Midjourney und DALL-E, setzten neue Maßstäbe in der Anwendung von KI zur Erschaffung von Bildern aus reinen Textbeschreibungen. Beide nutzen fortgeschrittene neuronale Netze, um realistische oder fantasievolle Kunstwerke zu erzeugen, die für Menschen ohne technische Vorkenntnisse zugänglich sind.
Midjourney, entwickelt von Midjourney, Inc., brachte die Generative Adversarial Networks (GANs) auf die nächste Stufe, indem es Nutzern ermöglichte, fotorealistische oder künstlerisch interpretierte Bilder einfach per Texteingabe zu erstellen. GANs hatten zuvor in der Kunstwelt für Aufsehen gesorgt, doch Midjourney brachte diese Technologie endgültig in den Mainstream. Mit einer benutzerfreundlichen Plattform konnten Menschen ohne Programmiererfahrung kreative Kunstwerke erschaffen und ihre Visionen zum Leben erwecken.
Gleichzeitig machte DALL-E, entwickelt von OpenAI, durch seinen leistungsstarken Einsatz von „transformer“-basierten neuronalen Netzwerken einen ähnlichen Durchbruch. DALL-E ermöglicht es, detaillierte und fotorealistische Bilder basierend auf spezifischen Textbeschreibungen zu erzeugen, was nicht nur in künstlerischen, sondern auch in wissenschaftlichen und kommerziellen Bereichen Anwendung fand. DALL-E beeindruckte durch seine Fähigkeit, auf einfache Aufforderungen hin Bilder von extremer Detailtreue zu generieren, die von einfachen Objekten bis hin zu abstrakten Konzepten reichten.
Das Besondere an beiden Plattformen – Midjourney und DALL-E – war nicht nur die atemberaubende Qualität der generierten Bilder, sondern auch ihre Zugänglichkeit. Nutzer konnten auf „Knopfdruck“ kreative Inhalte erstellen, ohne tiefgehende technische Kenntnisse zu benötigen. Diese Demokratisierung der Kunst durch KI stellte einen revolutionären Schritt dar, der GAN-Technologien und transformer-basierte Netzwerke wie nie zuvor in den Mainstream brachte. Sowohl Midjourney als auch DALL-E ermöglichen es Künstlern, Designern und Laien, ihre kreativen Ideen mit der Hilfe leistungsstarker KI-Technologie zu verwirklichen und haben damit die Art und Weise, wie wir über Kunst und Kreativität denken, fundamental verändert.
2022: ChatGPT 3.5 – Der Durchbruch in der menschlichen Kommunikation
ChatGPT 3.5, entwickelt von OpenAI, sorgte ebenfalls 2022 für Furore und setzte neue Maßstäbe in der Fähigkeit von Chatbots, natürlich und menschenähnlich zu kommunizieren. Auf Basis der GPT-3.5-Architektur brachte diese Version bemerkenswerte Verbesserungen in der Textverarbeitung und dem Verstehen komplexer menschlicher Ausdrucksformen wie Ironie, Witz und sogar emotionaler Nuancen.
Ein bahnbrechendes Merkmal von ChatGPT 3.5 war seine Fähigkeit, Konversationen auf einem weit höheren Niveau zu führen als seine Vorgängermodelle. Es konnte Fragen beantworten, komplexe Sachverhalte erklären, kreative Texte schreiben und sogar Programmcode generieren. Die Fähigkeit, Ironie und Humor zu erkennen und adäquat darauf zu reagieren, war besonders bemerkenswert und brachte Chatbots näher an menschliche Interaktionen heran als je zuvor.
ChatGPT 3.5 schaffte es zudem, im Mainstream anzukommen, da es immer häufiger in alltäglichen Anwendungen integriert wurde – von Kundensupport-Systemen über persönliche Assistenten bis hin zu kreativen Tools. Seine beeindruckende Vielseitigkeit ermöglichte es der breiten Öffentlichkeit, von den Vorteilen dieser fortschrittlichen KI-Technologie zu profitieren. Die Fähigkeit von ChatGPT, große Mengen an Informationen zu verarbeiten und in natürliche Konversationen einzubringen, machte es zu einem unverzichtbaren Werkzeug in vielen Bereichen, von der Bildung bis hin zur Geschäftskommunikation.